publications
2024
-
 PAIR-Diffusion: A Comprehensive Multimodal Object-Level Image EditorVidit Goel*, Elia Peruzzo*, Yifan Jiang, and 5 more authorsIn CVPR, 2024
PAIR-Diffusion: A Comprehensive Multimodal Object-Level Image EditorVidit Goel*, Elia Peruzzo*, Yifan Jiang, and 5 more authorsIn CVPR, 2024Image editing using diffusion models has witnessed extremely fast-paced growth recently. There are various ways in which previous works enable controlling and editing images. Some works use high-level conditioning such as text, while others use low-level conditioning. Nevertheless, most of them lack fine-grained control over the properties of the different objects present in the image, i.e. object-level image editing. In this work, we consider an image as a composition of multiple objects, each defined by various properties. Out of these properties, we identify structure and appearance as the most intuitive to understand and useful for editing purposes. We propose Structure-and-Appearance Paired Diffusion model (PAIR-Diffusion), which is trained using structure and appearance information explicitly extracted from the images. The proposed model enables users to inject a reference image’s appearance into the input image at both the object and global levels. Additionally, PAIR-Diffusion allows editing the structure while maintaining the style of individual components of the image unchanged. We extensively evaluate our method on LSUN datasets and the CelebA-HQ face dataset, and we demonstrate fine-grained control over both structure and appearance at the object level. We also applied the method to Stable Diffusion to edit any real image at the object level.
@inproceedings{goel2023pairdiffusion, title = {PAIR-Diffusion: A Comprehensive Multimodal Object-Level Image Editor}, author = {Goel*, Vidit and Peruzzo*, Elia and Jiang, Yifan and Xu, Dejia and Sebe, Nicu and Darrell, Trevor and Wang, Zhangyang and Shi, Humphrey}, year = {2024}, booktitle = {CVPR}, dimensions = {ture}, } -
 VASE: Object-Centric Appearance and Shape Manipulation of Real VideosElia Peruzzo, Vidit Goel, Dejia Xu, and 5 more authors2024
VASE: Object-Centric Appearance and Shape Manipulation of Real VideosElia Peruzzo, Vidit Goel, Dejia Xu, and 5 more authors2024Recently, several works tackled the video editing task fostered by the success of large-scale text-to-image generative models. However, most of these methods holistically edit the frame using the text, exploiting the prior given by foundation diffusion models and focusing on improving the temporal consistency across frames. In this work, we introduce a framework that is object-centric and is designed to control both the object’s appearance and, notably, to execute precise and explicit structural modifications on the object. We build our framework on a pre-trained image-conditioned diffusion model, integrate layers to handle the temporal dimension, and propose training strategies and architectural modifications to enable shape control. We evaluate our method on the image-driven video editing task showing similar performance to the state-of-the-art, and showcasing novel shape-editing capabilities.
@misc{peruzzo2024vase, title = {VASE: Object-Centric Appearance and Shape Manipulation of Real Videos}, author = {Peruzzo, Elia and Goel, Vidit and Xu, Dejia and Xu, Xingqian and Jiang, Yifan and Wang, Zhangyang and Shi, Humphrey and Sebe, Nicu}, year = {2024}, eprint = {2401.02473}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, } -
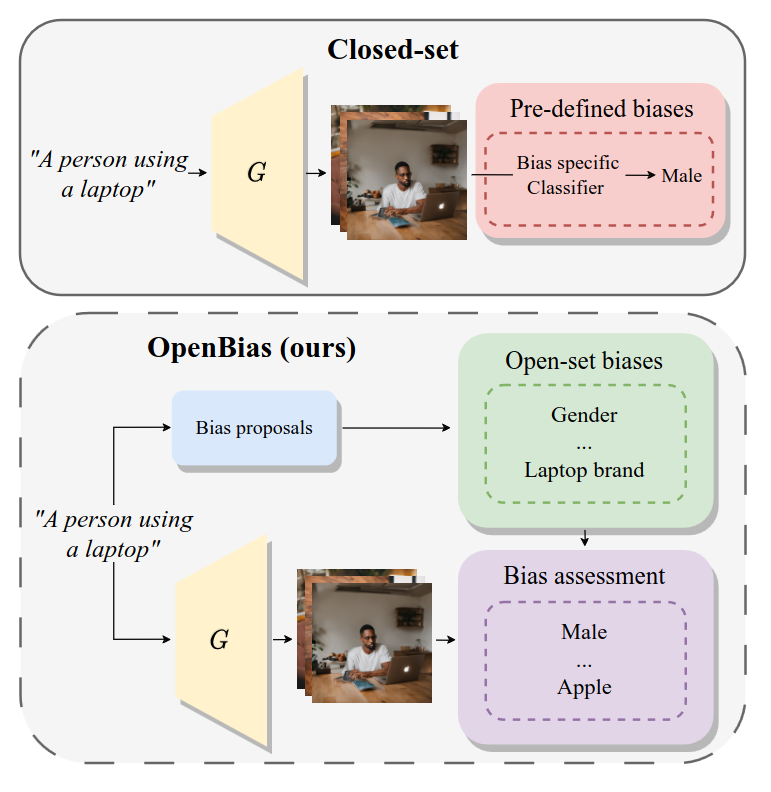 OpenBias: Open-set Bias Detection in Text-to-Image Generative ModelsMoreno D’Incà, Elia Peruzzo, Massimiliano Mancini, and 6 more authorsIn CVPR, 2024
OpenBias: Open-set Bias Detection in Text-to-Image Generative ModelsMoreno D’Incà, Elia Peruzzo, Massimiliano Mancini, and 6 more authorsIn CVPR, 2024Text-to-image generative models are becoming increasingly popular and accessible to the general public. As these models see large-scale deployments, it is necessary to deeply investigate their safety and fairness to not disseminate and perpetuate any kind of biases. However, existing works focus on detecting closed sets of biases defined a priori, limiting the studies to well-known concepts. In this paper, we tackle the challenge of open-set bias detection in text-to-image generative models presenting OpenBias, a new pipeline that identifies and quantifies the severity of biases agnostically, without access to any precompiled set. OpenBias has three stages. In the first phase, we leverage a Large Language Model (LLM) to propose biases given a set of captions. Secondly, the target generative model produces images using the same set of captions. Lastly, a Vision Question Answering model recognizes the presence and extent of the previously proposed biases. We study the behavior of Stable Diffusion 1.5, 2, and XL emphasizing new biases, never investigated before. Via quantitative experiments, we demonstrate that OpenBias agrees with current closed-set bias detection methods and human judgement.
@inproceedings{d2024openbias, title = {OpenBias: Open-set Bias Detection in Text-to-Image Generative Models}, author = {D'Inc{\`a}, Moreno and Peruzzo, Elia and Mancini, Massimiliano and Xu, Dejia and Goel, Vidit and Xu, Xingqian and Wang, Zhangyang and Shi, Humphrey and Sebe, Nicu}, year = {2024}, booktitle = {CVPR}, dimensions = {true}, }
2023
-
 Interactive Neural PaintingElia Peruzzo, Willi Menapace, Vidit Goel, and 8 more authorsComputer Vision and Image Understanding, 2023
Interactive Neural PaintingElia Peruzzo, Willi Menapace, Vidit Goel, and 8 more authorsComputer Vision and Image Understanding, 2023In the last few years, Neural Painting (NP) techniques became capable of producing extremely realistic artworks. This paper advances the state of the art in this emerging research domain by proposing the first approach for Interactive NP. Considering a setting where a user looks at a scene and tries to reproduce it on a painting, our objective is to develop a computational framework to assist the user’s creativity by suggesting the next strokes to paint, that can be possibly used to complete the artwork. To accomplish such a task, we propose I-Paint, a novel method based on a conditional transformer Variational AutoEncoder (VAE) architecture with a two-stage decoder. To evaluate the proposed approach and stimulate research in this area, we also introduce two novel datasets. Our experiments show that our approach provides good stroke suggestions and compares favorably to the state of the art.
@article{peruzzo2023interactive, title = {Interactive Neural Painting}, author = {Peruzzo, Elia and Menapace, Willi and Goel, Vidit and Arrigoni, Federica and Tang, Hao and Xu, Xingqian and Chopikyan, Arman and Orlov, Nikita and Hu, Yuxiao and Shi, Humphrey and others}, journal = {Computer Vision and Image Understanding}, volume = {235}, pages = {103778}, year = {2023}, dimensions = {true}, publisher = {Elsevier}, } -
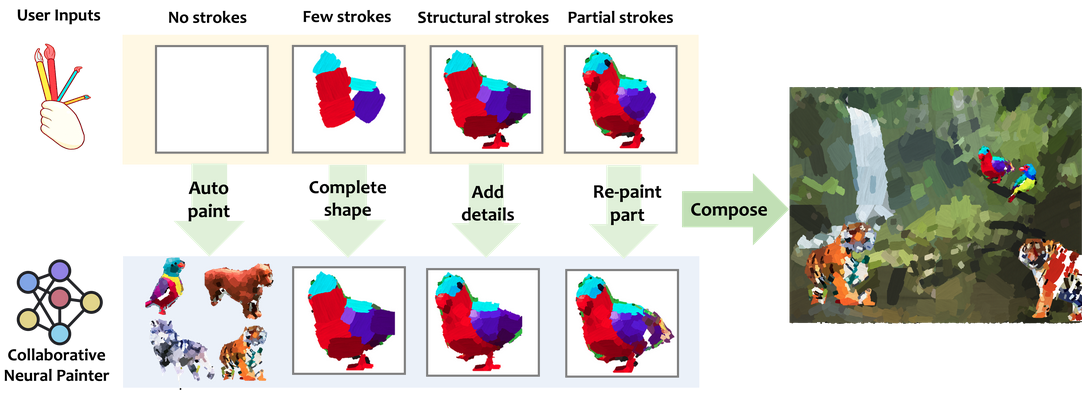 Collaborative Neural PaintingNicola Dall’Asen, Willi Menapace, Elia Peruzzo, and 3 more authors2023
Collaborative Neural PaintingNicola Dall’Asen, Willi Menapace, Elia Peruzzo, and 3 more authors2023The process of painting fosters creativity and rational planning. However, existing generative AI mostly focuses on producing visually pleasant artworks, without emphasizing the painting process. We introduce a novel task, Collaborative Neural Painting (CNP), to facilitate collaborative art painting generation between humans and machines. Given any number of user-input brushstrokes as the context or just the desired object class, CNP should produce a sequence of strokes supporting the completion of a coherent painting. Importantly, the process can be gradual and iterative, so allowing users’ modifications at any phase until the completion. Moreover, we propose to solve this task using a painting representation based on a sequence of parametrized strokes, which makes it easy both editing and composition operations. These parametrized strokes are processed by a Transformer-based architecture with a novel attention mechanism to model the relationship between the input strokes and the strokes to complete. We also propose a new masking scheme to reflect the interactive nature of CNP and adopt diffusion models as the basic learning process for its effectiveness and diversity in the generative field. Finally, to develop and validate methods on the novel task, we introduce a new dataset of painted objects and an evaluation protocol to benchmark CNP both quantitatively and qualitatively. We demonstrate the effectiveness of our approach and the potential of the CNP task as a promising avenue for future research.
@misc{dallasen2023collaborative, title = {Collaborative Neural Painting}, author = {Dall'Asen, Nicola and Menapace, Willi and Peruzzo, Elia and Sangineto, Enver and Wang, Yiming and Ricci, Elisa}, year = {2023}, eprint = {2312.01800}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, dimensions = {true}, }
2022
-
 Spatial Entropy as an Inductive Bias for Vision TransformersElia Peruzzo, Enver Sangineto, Yahui Liu, and 4 more authorsMachine Learning Journal, 2022
Spatial Entropy as an Inductive Bias for Vision TransformersElia Peruzzo, Enver Sangineto, Yahui Liu, and 4 more authorsMachine Learning Journal, 2022Recent work has shown that the attention maps of Vision Transformers (VTs), when trained with self-supervision, can contain a semantic segmentation structure which does not spontaneously emerge when training is supervised. In this paper, we explicitly encourage the emergence of this spatial clustering as a form of training regularization, this way including a self-supervised pretext task into the standard supervised learning. In more detail, we propose a VT regularization method based on a spatial formulation of the information entropy. By minimizing the proposed spatial entropy, we explicitly ask the VT to produce spatially ordered attention maps, this way including an object-based prior during training. Using extensive experiments, we show that the proposed regularization approach is beneficial with different training scenarios, datasets, downstream tasks and VT architectures. The code will be available upon acceptance.
doi = {10.48550/ARXIV.2206.04636}, author = {Peruzzo, Elia and Sangineto, Enver and Liu, Yahui and De Nadai, Marco and Bi, Wei and Lepri, Bruno and Sebe, Nicu}, keywords = {Computer Vision and Pattern Recognition (cs.CV), Machine Learning (cs.LG), FOS: Computer and information sciences, FOS: Computer and information sciences}, title = {Spatial Entropy as an Inductive Bias for Vision Transformers}, publisher = {Elsevier}, year = {2022}, copyright = {arXiv.org perpetual, non-exclusive license}, journal = {Machine Learning Journal}, dimensions = {true}, } - Artificial Intelligence You Can Trust: What Matters Beyond Performance When Applying Artificial Intelligence to Renal Histopathology?.John O.O. Ayorinde, Federica Citterio, Matteo Landrò, and 8 more authorsIn Journal of the American Society of Nephrology, 2022
Although still in its infancy, artificial intelligence (AI) analysis of kidney biopsy images is anticipated to become an integral aspect of renal histopathology. As these systems are developed, the focus will understandably be on developing ever more accurate models, but successful translation to the clinic will also depend upon other characteristics of the system. In the extreme, deployment of highly performant but “black box” AI is fraught with risk, and high-profile errors could damage future trust in the technology. Furthermore, a major factor determining whether new systems are adopted in clinical settings is whether they are “trusted” by clinicians. Key to unlocking trust will be designing platforms optimized for intuitive human-AI interactions and ensuring that, where judgment is required to resolve ambiguous areas of assessment, the workings of the AI image classifier are understandable to the human observer. Therefore, determining the optimal design for AI systems depends on factors beyond performance, with considerations of goals, interpretability, and safety constraining many design and engineering choices. In this article, we explore challenges that arise in the application of AI to renal histopathology, and consider areas where choices around model architecture, training strategy, and workflow design may be influenced by factors beyond the final performance metrics of the system.
author = {Ayorinde, John O.O. and Citterio, Federica and Landrò, Matteo and Peruzzo, Elia and Islam, Tuba and Tilley, Simon and Taylor, Geoffrey and Bardsley, Victoria and Liò, Pietro and Samoshkin, Alex and Pettigrew, Gavin J.}, title = {Artificial Intelligence You Can Trust: What Matters Beyond Performance When Applying Artificial Intelligence to Renal Histopathology?.}, booktitle = {Journal of the American Society of Nephrology}, pages = {2133-2140}, year = {2022}, }
2019
- APCCASMorphological Residue Encoding and Piecewise Approximation Techniques for Lossless Binary Image CompressionElia Peruzzo, and Jian-Jiun DingIn IEEE Asia Pacific Conference on Circuits and Systems, 2019
@inproceedings{8953151, author = {Peruzzo, Elia and Ding, Jian-Jiun}, booktitle = {IEEE Asia Pacific Conference on Circuits and Systems}, title = {Morphological Residue Encoding and Piecewise Approximation Techniques for Lossless Binary Image Compression}, year = {2019}, pages = {353-356}, }