Elia Peruzzo
PhD @ unitn

via Sommarive, 9, Povo
Trento, Italy
Hey, I’m a Ph.D Student at the University of Trento where I work with Prof. Nicu Sebe and Prof. Elisa Ricci at the MHUG Group.
My research interests focus on applications of deep learning techniques for controllable and editable image/video generation.
contact: elia [dot] peruzzo [at] gmail [dot] com
selected publications
-
 PAIR-Diffusion: A Comprehensive Multimodal Object-Level Image EditorVidit Goel*, Elia Peruzzo*, Yifan Jiang, and 5 more authorsIn CVPR, 2024
PAIR-Diffusion: A Comprehensive Multimodal Object-Level Image EditorVidit Goel*, Elia Peruzzo*, Yifan Jiang, and 5 more authorsIn CVPR, 2024Image editing using diffusion models has witnessed extremely fast-paced growth recently. There are various ways in which previous works enable controlling and editing images. Some works use high-level conditioning such as text, while others use low-level conditioning. Nevertheless, most of them lack fine-grained control over the properties of the different objects present in the image, i.e. object-level image editing. In this work, we consider an image as a composition of multiple objects, each defined by various properties. Out of these properties, we identify structure and appearance as the most intuitive to understand and useful for editing purposes. We propose Structure-and-Appearance Paired Diffusion model (PAIR-Diffusion), which is trained using structure and appearance information explicitly extracted from the images. The proposed model enables users to inject a reference image’s appearance into the input image at both the object and global levels. Additionally, PAIR-Diffusion allows editing the structure while maintaining the style of individual components of the image unchanged. We extensively evaluate our method on LSUN datasets and the CelebA-HQ face dataset, and we demonstrate fine-grained control over both structure and appearance at the object level. We also applied the method to Stable Diffusion to edit any real image at the object level.
@inproceedings{goel2023pairdiffusion, title = {PAIR-Diffusion: A Comprehensive Multimodal Object-Level Image Editor}, author = {Goel*, Vidit and Peruzzo*, Elia and Jiang, Yifan and Xu, Dejia and Sebe, Nicu and Darrell, Trevor and Wang, Zhangyang and Shi, Humphrey}, year = {2024}, booktitle = {CVPR}, dimensions = {ture}, } -
 VASE: Object-Centric Appearance and Shape Manipulation of Real VideosElia Peruzzo, Vidit Goel, Dejia Xu, and 5 more authors2024
VASE: Object-Centric Appearance and Shape Manipulation of Real VideosElia Peruzzo, Vidit Goel, Dejia Xu, and 5 more authors2024Recently, several works tackled the video editing task fostered by the success of large-scale text-to-image generative models. However, most of these methods holistically edit the frame using the text, exploiting the prior given by foundation diffusion models and focusing on improving the temporal consistency across frames. In this work, we introduce a framework that is object-centric and is designed to control both the object’s appearance and, notably, to execute precise and explicit structural modifications on the object. We build our framework on a pre-trained image-conditioned diffusion model, integrate layers to handle the temporal dimension, and propose training strategies and architectural modifications to enable shape control. We evaluate our method on the image-driven video editing task showing similar performance to the state-of-the-art, and showcasing novel shape-editing capabilities.
@misc{peruzzo2024vase, title = {VASE: Object-Centric Appearance and Shape Manipulation of Real Videos}, author = {Peruzzo, Elia and Goel, Vidit and Xu, Dejia and Xu, Xingqian and Jiang, Yifan and Wang, Zhangyang and Shi, Humphrey and Sebe, Nicu}, year = {2024}, eprint = {2401.02473}, archiveprefix = {arXiv}, primaryclass = {cs.CV}, } -
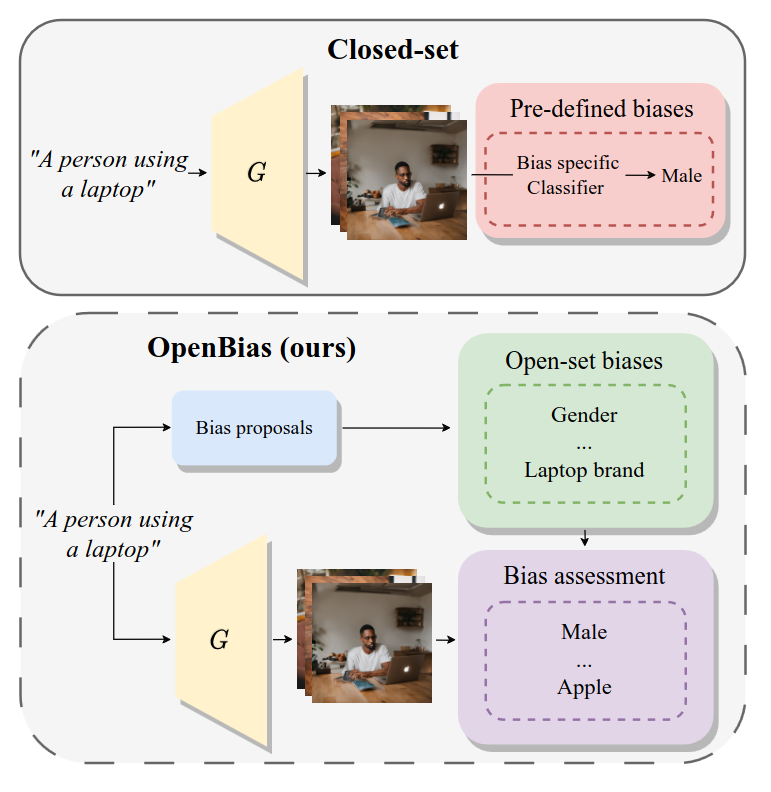 OpenBias: Open-set Bias Detection in Text-to-Image Generative ModelsMoreno D’Incà, Elia Peruzzo, Massimiliano Mancini, and 6 more authorsIn CVPR, 2024
OpenBias: Open-set Bias Detection in Text-to-Image Generative ModelsMoreno D’Incà, Elia Peruzzo, Massimiliano Mancini, and 6 more authorsIn CVPR, 2024Text-to-image generative models are becoming increasingly popular and accessible to the general public. As these models see large-scale deployments, it is necessary to deeply investigate their safety and fairness to not disseminate and perpetuate any kind of biases. However, existing works focus on detecting closed sets of biases defined a priori, limiting the studies to well-known concepts. In this paper, we tackle the challenge of open-set bias detection in text-to-image generative models presenting OpenBias, a new pipeline that identifies and quantifies the severity of biases agnostically, without access to any precompiled set. OpenBias has three stages. In the first phase, we leverage a Large Language Model (LLM) to propose biases given a set of captions. Secondly, the target generative model produces images using the same set of captions. Lastly, a Vision Question Answering model recognizes the presence and extent of the previously proposed biases. We study the behavior of Stable Diffusion 1.5, 2, and XL emphasizing new biases, never investigated before. Via quantitative experiments, we demonstrate that OpenBias agrees with current closed-set bias detection methods and human judgement.
@inproceedings{d2024openbias, title = {OpenBias: Open-set Bias Detection in Text-to-Image Generative Models}, author = {D'Inc{\`a}, Moreno and Peruzzo, Elia and Mancini, Massimiliano and Xu, Dejia and Goel, Vidit and Xu, Xingqian and Wang, Zhangyang and Shi, Humphrey and Sebe, Nicu}, year = {2024}, booktitle = {CVPR}, dimensions = {true}, } -
 Interactive Neural PaintingElia Peruzzo, Willi Menapace, Vidit Goel, and 8 more authorsComputer Vision and Image Understanding, 2023
Interactive Neural PaintingElia Peruzzo, Willi Menapace, Vidit Goel, and 8 more authorsComputer Vision and Image Understanding, 2023In the last few years, Neural Painting (NP) techniques became capable of producing extremely realistic artworks. This paper advances the state of the art in this emerging research domain by proposing the first approach for Interactive NP. Considering a setting where a user looks at a scene and tries to reproduce it on a painting, our objective is to develop a computational framework to assist the user’s creativity by suggesting the next strokes to paint, that can be possibly used to complete the artwork. To accomplish such a task, we propose I-Paint, a novel method based on a conditional transformer Variational AutoEncoder (VAE) architecture with a two-stage decoder. To evaluate the proposed approach and stimulate research in this area, we also introduce two novel datasets. Our experiments show that our approach provides good stroke suggestions and compares favorably to the state of the art.
@article{peruzzo2023interactive, title = {Interactive Neural Painting}, author = {Peruzzo, Elia and Menapace, Willi and Goel, Vidit and Arrigoni, Federica and Tang, Hao and Xu, Xingqian and Chopikyan, Arman and Orlov, Nikita and Hu, Yuxiao and Shi, Humphrey and others}, journal = {Computer Vision and Image Understanding}, volume = {235}, pages = {103778}, year = {2023}, dimensions = {true}, publisher = {Elsevier}, }